· Dave Brewster (dave@augustdata.ai) · rag · 7 min read
RAG: How do you configure storage?
Part 2: How is RAG storage configured in Eidolon.
This is Part 2 of a 3 part series on Retrieval-Augmented Generation.
For general information on RAG, see Part 1: Define RAG and its components.
For information on configuring RAG retrieval in Eidolon, see Part 3: How is RAG retrieval configured in Eidolon.
In the last post we discussed what RAG is and how it works. We also showed a brief introduction to the RetrieverAgent in Eidolon and the most basic configuration of it.
In this post we will dive deeper into the storage configuration of the RetrieverAgent, the components that make up the storage pipeline and how to configure them.
Storage Pipeline
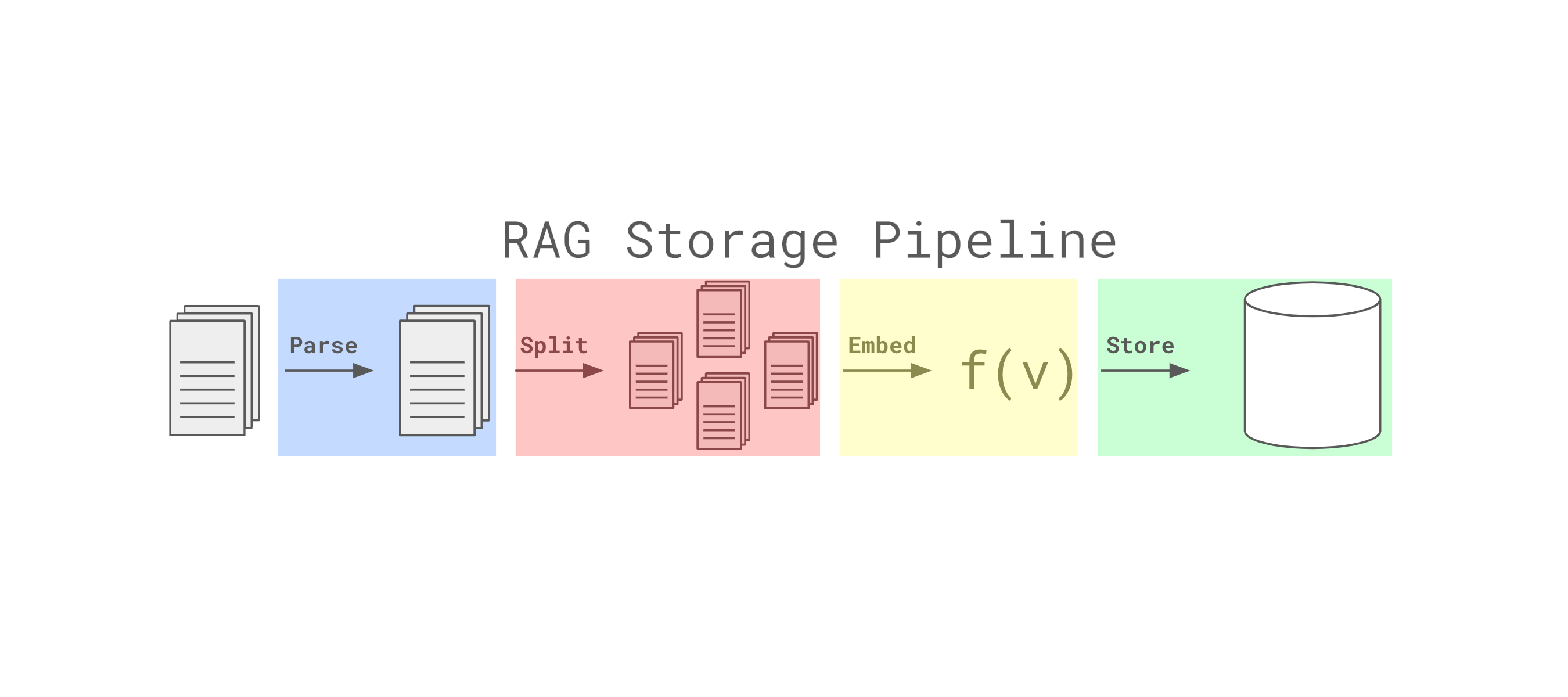
The storage pipeline in Eidolon can be broken down into 5 main parts:
- Loading: This is the first step in the pipeline. It is responsible for streaming data from the storage medium. A loader can be something simple like a file reader, or something more complex like a GitHub repository reader.
- Parsing: This is the second step in the pipeline. It is responsible for parsing the data that was loaded into text or image data. As of this writing, Eidolon supports the following parsers:
- AutoParser: A parser that is used to automatically detect the type of data and use the appropriate parser for it.
- TextParsers: Parsers that are used to parse text data like raw text, json, xml, etc…
- PDFParser: A parser that is used to parse PDF files into text data.
- CodeParsers: Parsers that are used to parse code files into text data. In particular, these are used to split code files into semantic chunks that make sense for the language.
- HTMLParser: A parser that is used to parse HTML files into text data. We use BeautifulSoup for this.
- Splitting: This is the third step in the pipeline. It is responsible for splitting the parsed data into smaller chunks. This is useful for large documents that are too big to be processed in one go. As of this writing, Eidolon supports the following splitters:
- SentenceSplitter: A splitter that is used to split text data into sentences.
- RecursiveCharacterTextSplitter: A splitter that is used to split text data into characters recursively. It optimizes for the longest possible chunks that fit into a region and are split by section, paragraph, sentence, or word, in that order.
- CodeSplitter: A splitter that is used to split code data into semantic chunks.
- HTMLSplitter: A splitter that is used to split HTML data into text data on semantic boundaries.
- MarkdownSplitter: A splitter that is used to split markdown data into text data on semantic boundaries.
- Storage: This is the final step in the pipeline. It is responsible for storing the split data in memory. It does this by adding each split first to SemanticMemory and then to the SimilarityMemory defined on the machine.
- Monitoring: This is an optional step in the pipeline. It is responsible for monitoring the loader and automatically reloading the data if it changes, deleting chunks that are no longer present, and adding new files.
RetrieverAgent
The RetrieverAgent is the top level component that manages the storage pipeline and exposes two method for search and retrieval of documents. The RetrieverAgent is broken down into two main components, the ‘retrieve’ methods and an instance of a DocumentManger. The DocumentManager is responsible for managing the storage pipeline which will discuss in detail here.
DocumentManager
The DocumentManager is broken down into to two main components, the loader and the document processor.
The loader is responsible for streaming data from the storage medium. To implement a loader, you need to implement the Loader interface. The Loader interface has two methods that need to be implemented:
class DocumentLoader(ABC, Specable[DocumentLoaderSpec]): logger = logging.getLogger("eidolon")
@abstractmethod async def get_changes(self, metadata: Dict[str, Dict[str, Any]]) -> AsyncIterator[FileChange]: pass
@abstractmethod async def list_files(self) -> AsyncIterator[str]: passThe get_changes method is responsible for returning an async iterator of FileChange objects. The FileChange object is a simple data class that contains the path to the file and the type of change that occurred.
The list_files method is responsible for returning an async iterator of file paths.
There are currently a few loaders implemented in Eidolon, a simple FileSystemLoader and a GitHubLoader. The FileSystemLoader is used to load data from the local file system and the GitHubLoader is used to load data from a GitHub repository.
We definitely need help implementing other loaders! Have a look at our GitHub repo on how to contribute to Eidolon
The document processor is responsible for adding, removing, and replacing processed documents. The DocumentProcessor uses two configurable components, the Parser and the Splitter.
All implementations of the DocumentParser must implement the following interface:
class DocumentParser(ABC, Specable[DocumentParserSpec]): @abstractmethod def parse(self, blob: DataBlob) -> Iterable[Document]: passThe parse method is responsible for taking a DataBlob object and returning an iterable of Document objects. The DataBlob object is a simple data class that contains the path to the file and methods to read the data. The Document object is a simple data class that contains the text data and metadata.
Parser implementations are responsible for parsing the given binary data and extracting text data from it. For example, the PDFParser is responsible for parsing PDF files into text data. The HTMLParser is responsible for parsing HTML files, using BeautifulSoup, into text data, keeping semantic boundaries in mind.
All implementations of the DocumentSplitter must implement the following interface:
class DocumentTransformer(ABC): @abstractmethod def transform_documents(self, documents: Iterable[Document], **kwargs: Any) -> Iterable[Document]: passThe transform_documents method is responsible for taking an iterable of Document objects, splitting them on semantic boundaries, and returning an iterable of Document objects. The main purpose of the splitter is to split large documents into smaller chunks that can be processed in parallel and to split documents on semantic boundaries. For example, a splitter might split a word document by section boundaries, a code document by function boundaries, or an HTML document by paragraph boundaries.
Each of these components can be used in isolation or as part of a different pipeline. The DocumentManager is a simple built-in pipeline, but larger, more complex pipelines are possible by assembling these components in different ways.
Configuration of the RetrieverAgent
The RetrieverAgent, like every component in Eidolon, is configured using a YAML file. The configuration for the RAGAgent follows its specification, with a few twists that should make it easier to configure.
There are two main sections of the configuration for the RetrieverAgent, the document_manager and the retriever information configured on the base class RetrievalSpec object. In this section we will focus on the document_manager configuration. The next article will focus on the retriever configuration.
The document_manager configuration is defined by the following Spec:
class DocumentManagerSpec(BaseModel): name: str recheck_frequency: int = Field(default=60, description="The number of seconds between checks.") loader: AnnotatedReference[DocumentLoader] doc_processor: AnnotatedReference[DocumentProcessor]The name field is a string that is used to identify the DocumentManager in the logs. The recheck_frequency field is an integer that is used to determine how often the loader should check for changes, in seconds. The loader field is a reference to the Loader implementation that should be used to load data. The doc_processor field is a reference to the DocumentProcessor implementation that should be used to process the data.
The loader and doc_processor fields are references to the implementations of the Loader and DocumentProcessor interfaces. The configuration of the loader is dependent on the implementation of the loader. An example configuration for the FileSystemLoader is included below.
The configuration of the DocumentProcessor is as follows:
class DocumentProcessorSpec(BaseModel): parser: AnnotatedReference[DocumentParser] splitter: AnnotatedReference[DocumentTransformer]The parser field is a reference to the DocumentParser implementation that should be used to parse the data. The splitter field is a reference to the DocumentTransformer implementation that should be used to split the data. Each of these are dependent on the implementation of the parser and splitter and usually don’t require any additional configuration.
Here is an example configuration for a RetrieverAgent that searches the Eidolon GitHub repository for code, examples, and documentation:
apiVersion: server.eidolonai.com/v1alpha1kind: Agentmetadata: name: repo_search
spec: implementation: RetrieverAgent name: "example_search" description: "Search the Eidolon github repository for code, examples, and documentation" document_manager: loader: implementation: GitHubLoader owner: "eidolon-ai" repo: "eidolon" pattern: - "examples/**/getting_started/**/*.yaml" - "examples/**/git_search/**/*.yaml" - "**/*.md" - "**/*.py" exclude: "**/test/**/*"Of note here, we use the GitHubLoader to load data from the Eidolon GitHub repository including all markdown and python files, but excluding any files in the test directories.
Conclusion
In this post we discussed the storage pipeline in Eidolon, the components that make up the pipeline, and how to configure them. We also discussed the DocumentManager and how to configure it.
In the next post we will discuss the retriever part of the RetrieverAgent and how to configure it.